Summary:
Brotli response decoding was introduced via https://github.com/facebook/flipper/pull/4288, and released in 0.177.0. We noticed from that release that many of our iOS response bodies were not being rendered. It simply showed `(empty)` in the `Response Body` section.
As noted in the gzip decoder ([here](2a52656d0b/desktop/plugins/public/network/utils.tsx (L117-L119))) within Flipper, iOS already provides an inflated `data` value, so it doesn't need inflating again.
This PR adds a best-effort guess to detect when the same problem arises in the Brotli decoder.
I'm definitely not a Brotli expert, but according to [this SO post](https://stackoverflow.com/questions/39008957/is-there-a-way-to-check-if-a-buffer-is-in-brotli-compressed-format), there's no sure-fire way to detect Brotli data, and some blobs of random data will still present as Brotli. We may still occasionally see false positives that continue to show `(empty)`, however in my testing, all of our server responses have rendered JSON responses perfectly.
The library used for decoding doesn't throw an error on failure with any responses we've seen, it just simply returns a 0-length buffer. So the naïve approach taken in this PR simply looks for a 0-length output buffer on a non-zero-length input buffer, and concludes "probably not Brotli, shrug emoji".
## Changelog
Ignore Brotli decode result on 0-length return value
Pull Request resolved: https://github.com/facebook/flipper/pull/4632
Test Plan:
We can use Facebook's servers to test this. Fire up a RN app, and add the following somewhere you can run it:
```typescript
fetch('https://graph.facebook.com/facebook/picture?redirect=false', {
headers: {
'accept-encoding': 'br',
},
})
```
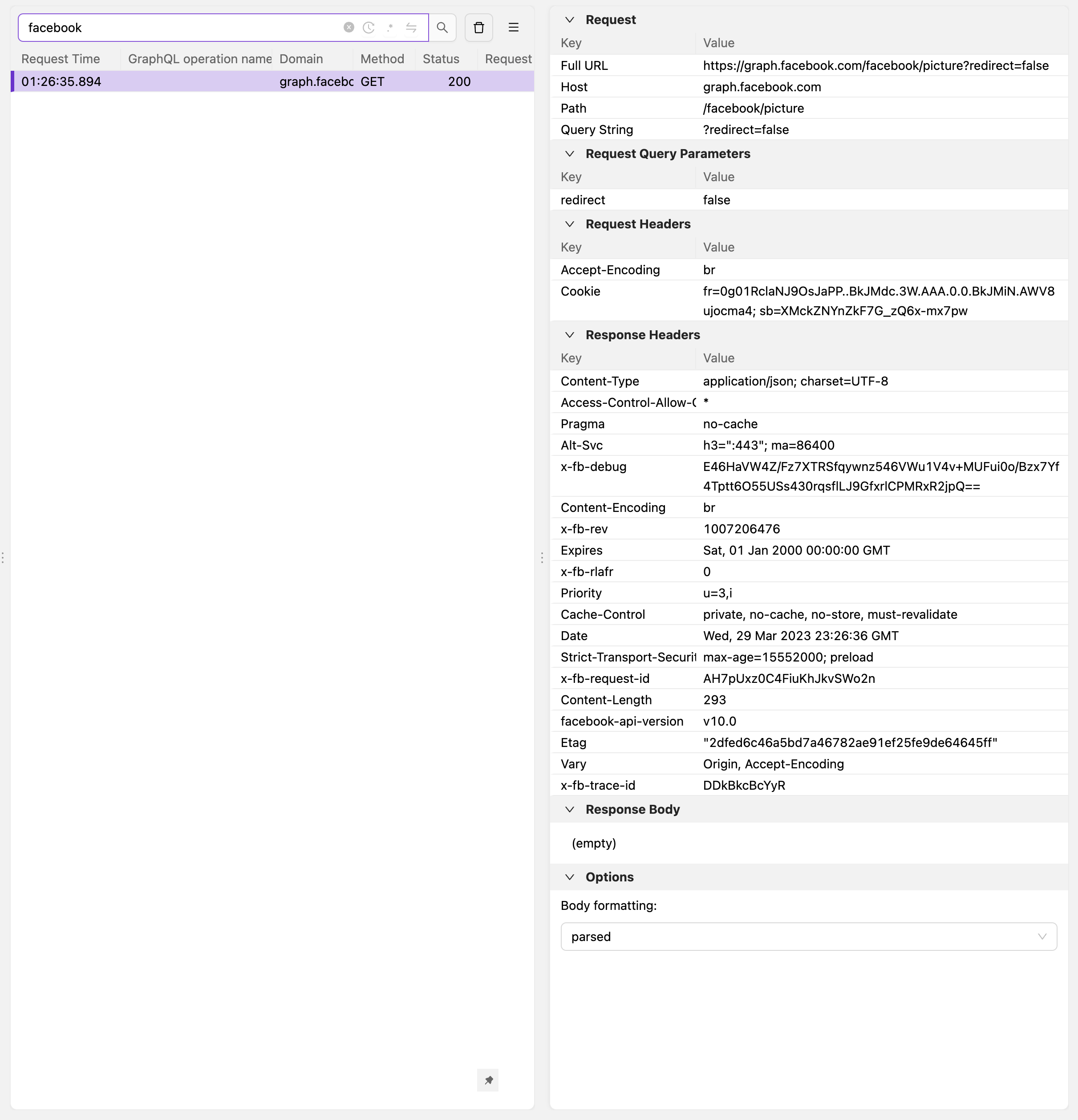
Before this patch, we can see that `Response Body` is `(empty)` in Flipper:
<img width="1211" alt="Screenshot 2023-03-30 at 1 26 48 am" src="https://user-images.githubusercontent.com/33126/228690254-988b5a01-5d7b-4ab3-b6dc-49f3b0607d10.png">
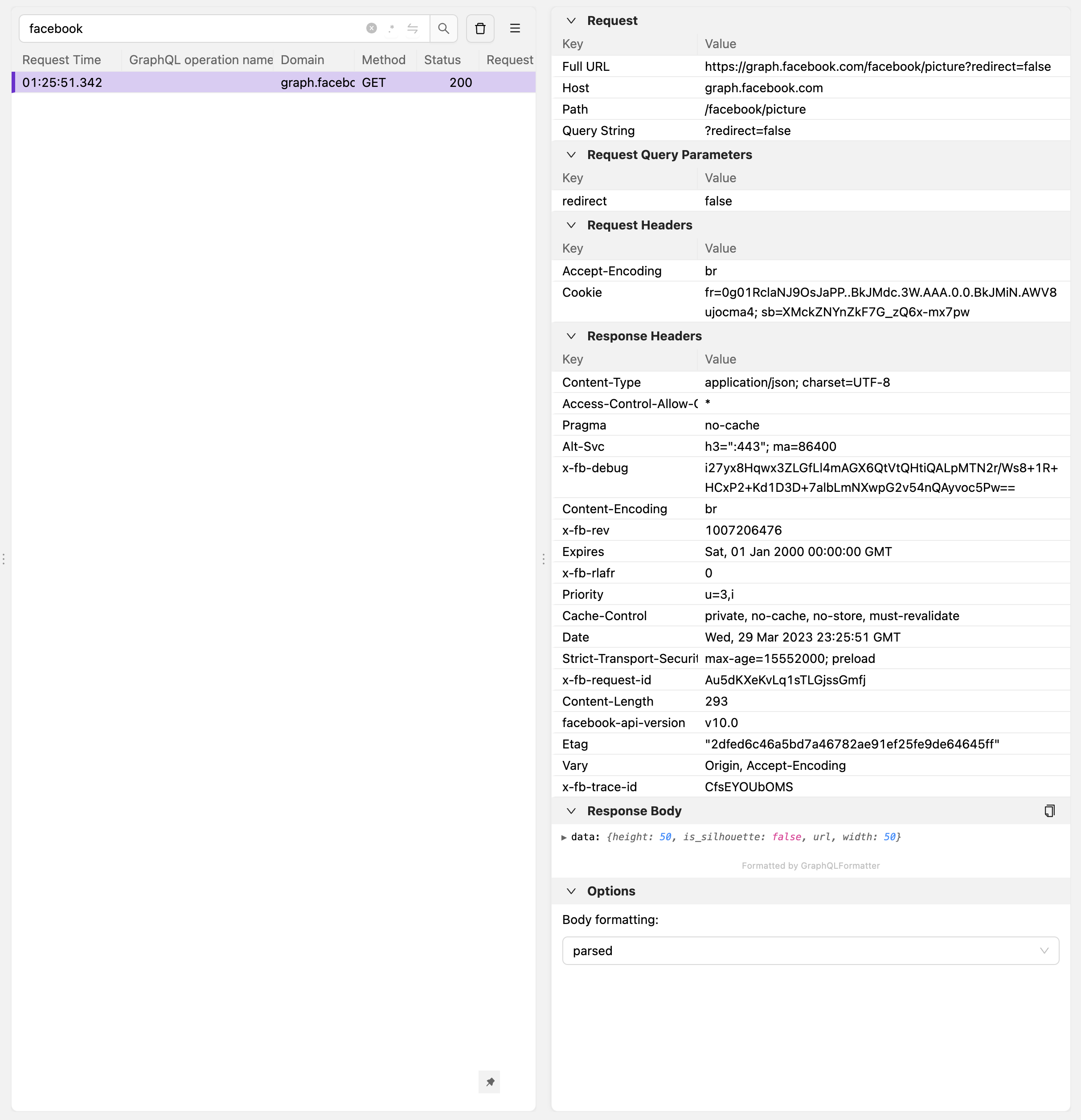
But after this patch, we can see some valid JSON in the `Response Body`:
<img width="1213" alt="Screenshot 2023-03-30 at 1 26 07 am" src="https://user-images.githubusercontent.com/33126/228690351-9611759a-5b7d-4ccb-9170-22b950c8afbe.png">
Most importantly, both responses have `Content-Encoding: br` headers.
Reviewed By: passy
Differential Revision: D46219337
Pulled By: mweststrate
fbshipit-source-id: 2ae775d381fa325c6d9e543bdbc617d1fd986671
{kind=link}
{kind=link}
324 lines
9.1 KiB
TypeScript
324 lines
9.1 KiB
TypeScript
/**
|
|
* Copyright (c) Meta Platforms, Inc. and affiliates.
|
|
*
|
|
* This source code is licensed under the MIT license found in the
|
|
* LICENSE file in the root directory of this source tree.
|
|
*
|
|
* @format
|
|
*/
|
|
|
|
import {Buffer} from 'buffer';
|
|
import decompress from 'brotli/decompress';
|
|
import pako from 'pako';
|
|
import {Request, Header, ResponseInfo} from './types';
|
|
import {Base64} from 'js-base64';
|
|
|
|
export function getHeaderValue(
|
|
headers: Array<Header> | undefined,
|
|
key: string,
|
|
): string {
|
|
if (!headers) {
|
|
return '';
|
|
}
|
|
for (const header of headers) {
|
|
if (header.key.toLowerCase() === key.toLowerCase()) {
|
|
return header.value;
|
|
}
|
|
}
|
|
return '';
|
|
}
|
|
|
|
// Matches `application/json` and `application/vnd.api.v42+json` (see https://jsonapi.org/#mime-types)
|
|
const jsonContentTypeRegex = new RegExp('application/(json|.+\\+json)');
|
|
const binaryContentType =
|
|
/^(application\/(zip|octet-stream|pdf))|(video|audio)|(image\/(png|webp|jpeg|gif|avif))$/;
|
|
|
|
export function isTextual(
|
|
headers?: Array<Header>,
|
|
body?: Uint8Array | string,
|
|
): boolean {
|
|
const contentType = getHeaderValue(headers, 'Content-Type');
|
|
// https://developer.mozilla.org/en-US/docs/Web/HTTP/Basics_of_HTTP/MIME_types
|
|
// https://developer.mozilla.org/en-US/docs/Web/HTTP/Basics_of_HTTP/MIME_types/Common_types
|
|
if (contentType) {
|
|
if (
|
|
contentType.startsWith('text/') ||
|
|
contentType.startsWith('application/x-www-form-urlencoded') ||
|
|
jsonContentTypeRegex.test(contentType) ||
|
|
contentType.startsWith('multipart/') ||
|
|
contentType.startsWith('message/') ||
|
|
contentType.startsWith('image/svg') ||
|
|
contentType.startsWith('application/xhtml+xml') ||
|
|
contentType.startsWith('application/xml')
|
|
) {
|
|
return true;
|
|
}
|
|
if (binaryContentType.test(contentType)) {
|
|
return false;
|
|
}
|
|
}
|
|
if (
|
|
(body instanceof Buffer || body instanceof Uint8Array) &&
|
|
isValidUtf8(body)
|
|
) {
|
|
return true;
|
|
}
|
|
return false;
|
|
}
|
|
|
|
function isValidUtf8(data: Uint8Array) {
|
|
if (data[0] === 0xef && data[1] === 0xbb && data[2] === 0xbf) {
|
|
return true; // valid utf8 BOM
|
|
}
|
|
// From https://weblog.rogueamoeba.com/2017/02/27/javascript-correctly-converting-a-byte-array-to-a-utf-8-string/
|
|
const extraByteMap = [1, 1, 1, 1, 2, 2, 3, 0];
|
|
const count = data.length;
|
|
|
|
for (let index = 0; index < count; ) {
|
|
let ch = data[index++];
|
|
if (ch & 0x80) {
|
|
let extra = extraByteMap[(ch >> 3) & 0x07];
|
|
if (!(ch & 0x40) || !extra || index + extra > count) return false;
|
|
|
|
ch &= 0x3f >> extra;
|
|
for (; extra > 0; extra -= 1) {
|
|
const chx = data[index++];
|
|
if ((chx & 0xc0) != 0x80) return false;
|
|
|
|
ch = (ch << 6) | (chx & 0x3f);
|
|
}
|
|
}
|
|
}
|
|
return true;
|
|
}
|
|
|
|
export function decodeBody(
|
|
headers?: Array<Header>,
|
|
data?: string | null,
|
|
): string | undefined | Uint8Array {
|
|
if (!data) {
|
|
return undefined;
|
|
}
|
|
|
|
try {
|
|
const contentEncoding = getHeaderValue(headers, 'Content-Encoding');
|
|
switch (contentEncoding) {
|
|
// Gzip encoding
|
|
case 'gzip': {
|
|
try {
|
|
// The request is gzipped, so convert the raw bytes back to base64 first.
|
|
const dataArr = Base64.toUint8Array(data);
|
|
// then inflate.
|
|
return isTextual(headers, dataArr)
|
|
? // pako will detect the BOM headers and return a proper utf-8 string right away
|
|
pako.inflate(dataArr, {to: 'string'})
|
|
: pako.inflate(dataArr);
|
|
} catch (e) {
|
|
// on iOS, the stream send to flipper is already inflated, so the content-encoding will not
|
|
// match the actual data anymore, and we should skip inflating.
|
|
// In that case, we intentionally fall-through
|
|
if (!('' + e).includes('incorrect header check')) {
|
|
throw e;
|
|
}
|
|
break;
|
|
}
|
|
}
|
|
|
|
// Brotli encoding (https://github.com/facebook/flipper/issues/2578)
|
|
case 'br': {
|
|
const inflated = decompress(Buffer.from(Base64.toUint8Array(data)));
|
|
|
|
// on iOS, the stream send to flipper is already inflated, so the content-encoding will not
|
|
// match the actual data anymore, so a 0-length result without an error is expected.
|
|
// In that case, we intentionally fall-through
|
|
if (inflated.length === 0 && data.length > 0) {
|
|
break;
|
|
}
|
|
|
|
return new TextDecoder().decode(inflated);
|
|
}
|
|
}
|
|
// If this is not a gzipped or brotli-encoded request, assume we are interested in a proper utf-8 string.
|
|
// - If the raw binary data in is needed, in base64 form, use data directly
|
|
// - either directly use data (for example)
|
|
const bytes = Base64.toUint8Array(data);
|
|
if (isTextual(headers, bytes)) {
|
|
return Base64.decode(data);
|
|
} else {
|
|
return bytes;
|
|
}
|
|
} catch (e) {
|
|
console.warn(
|
|
`Flipper failed to decode request/response body (size: ${data.length}): ${e}`,
|
|
);
|
|
return undefined;
|
|
}
|
|
}
|
|
|
|
export function convertRequestToCurlCommand(
|
|
request: Pick<Request, 'method' | 'url' | 'requestHeaders' | 'requestData'>,
|
|
): string {
|
|
let command: string = `curl -v -X ${request.method}`;
|
|
command += ` ${escapedString(request.url)}`;
|
|
// Add headers
|
|
request.requestHeaders.forEach((header: Header) => {
|
|
const headerStr = `${header.key}: ${header.value}`;
|
|
command += ` -H ${escapedString(headerStr)}`;
|
|
});
|
|
if (typeof request.requestData === 'string') {
|
|
command += ` -d ${escapedString(request.requestData)}`;
|
|
}
|
|
return command;
|
|
}
|
|
|
|
export function bodyAsString(body: undefined | string | Uint8Array): string {
|
|
if (body == undefined) {
|
|
return '(empty)';
|
|
}
|
|
if (body instanceof Uint8Array) {
|
|
return '(binary data)';
|
|
}
|
|
return body;
|
|
}
|
|
|
|
export function bodyAsBinary(
|
|
body: undefined | string | Uint8Array,
|
|
): Uint8Array | undefined {
|
|
if (body instanceof Uint8Array) {
|
|
return body;
|
|
}
|
|
return undefined;
|
|
}
|
|
|
|
export const queryToObj = (query: string) => {
|
|
const params = new URLSearchParams(query);
|
|
const obj: Record<string, any> = {};
|
|
params.forEach((value, key) => {
|
|
obj[key] = value;
|
|
});
|
|
return obj;
|
|
};
|
|
|
|
function escapeCharacter(x: string) {
|
|
const code = x.charCodeAt(0);
|
|
return code < 16 ? '\\u0' + code.toString(16) : '\\u' + code.toString(16);
|
|
}
|
|
|
|
const needsEscapingRegex = /[\u0000-\u001f\u007f-\u009f!]/g;
|
|
|
|
// Escape util function, inspired by Google DevTools. Works only for POSIX
|
|
// based systems.
|
|
function escapedString(str: string) {
|
|
if (needsEscapingRegex.test(str) || str.includes("'")) {
|
|
return (
|
|
"$'" +
|
|
str
|
|
.replace(/\\/g, '\\\\')
|
|
.replace(/\'/g, "\\'")
|
|
.replace(/\n/g, '\\n')
|
|
.replace(/\r/g, '\\r')
|
|
.replace(needsEscapingRegex, escapeCharacter) +
|
|
"'"
|
|
);
|
|
}
|
|
|
|
// Simply use singly quoted string.
|
|
return "'" + str + "'";
|
|
}
|
|
|
|
export function getResponseLength(response: ResponseInfo): number {
|
|
const lengthString = response.headers
|
|
? getHeaderValue(response.headers, 'content-length')
|
|
: undefined;
|
|
if (lengthString) {
|
|
return parseInt(lengthString, 10);
|
|
} else if (response.data) {
|
|
return Buffer.byteLength(response.data, 'base64');
|
|
}
|
|
return 0;
|
|
}
|
|
|
|
export function getRequestLength(request: Request): number {
|
|
const lengthString = request.requestHeaders
|
|
? getHeaderValue(request.requestHeaders, 'content-length')
|
|
: undefined;
|
|
if (lengthString) {
|
|
return parseInt(lengthString, 10);
|
|
} else if (request.requestData) {
|
|
return Buffer.byteLength(request.requestData, 'base64');
|
|
}
|
|
return 0;
|
|
}
|
|
|
|
export function formatDuration(duration: number | undefined) {
|
|
if (typeof duration === 'number') return duration + 'ms';
|
|
return '';
|
|
}
|
|
|
|
export function formatBytes(count: number | undefined): string {
|
|
if (typeof count !== 'number') {
|
|
return '';
|
|
}
|
|
if (count > 1024 * 1024) {
|
|
return (count / (1024.0 * 1024)).toFixed(1) + ' MB';
|
|
}
|
|
if (count > 1024) {
|
|
return (count / 1024.0).toFixed(1) + ' kB';
|
|
}
|
|
return count + ' B';
|
|
}
|
|
|
|
export function formatStatus(status: number | undefined) {
|
|
return status ? '' + status : '';
|
|
}
|
|
|
|
export function formatOperationName(requestData: string): string {
|
|
try {
|
|
const parsedData = JSON.parse(requestData);
|
|
return parsedData?.operationName;
|
|
} catch (_err) {
|
|
return '';
|
|
}
|
|
}
|
|
|
|
export function requestsToText(requests: Request[]): string {
|
|
const request = requests[0];
|
|
if (!request || !request.url) {
|
|
return '<empty request>';
|
|
}
|
|
|
|
let copyText = `# HTTP request for ${request.domain} (ID: ${request.id})
|
|
## Request
|
|
HTTP ${request.method} ${request.url}
|
|
${request.requestHeaders
|
|
.map(
|
|
({key, value}: {key: string; value: string}): string =>
|
|
`${key}: ${String(value)}`,
|
|
)
|
|
.join('\n')}`;
|
|
|
|
// TODO: we want decoding only for non-binary data! See D23403095
|
|
if (request.requestData) {
|
|
copyText += `\n\n${request.requestData}`;
|
|
}
|
|
if (request.status) {
|
|
copyText += `
|
|
|
|
## Response
|
|
HTTP ${request.status} ${request.reason}
|
|
${
|
|
request.responseHeaders
|
|
?.map(
|
|
({key, value}: {key: string; value: string}): string =>
|
|
`${key}: ${String(value)}`,
|
|
)
|
|
.join('\n') ?? ''
|
|
}`;
|
|
}
|
|
|
|
if (request.responseData) {
|
|
copyText += `\n\n${request.responseData}`;
|
|
}
|
|
return copyText;
|
|
}
|